This is a followup from my last post about what Scratch is.
I wanted to do an engineering deep dive that talks more about how it's built under the hood. Why? Because it's cool. Or at least, we think it's cool.
Version control for SaaS data
In the previous post, I talked about what Scratch enables for business operators (founders, product managers, marketers, sales reps), giving you a way to build a local AI brain for your workflows. It gives you a way to safely ingest and make edits to your SaaS data.
There's an obvious parallel in the engineering world: version control. As developers, we've taken version control for granted for years because it would be insanity to try and develop live products without it. We even moved our cloud infrastructure definitions into version control via Terraform.
Now that we're hooking up probabilistic text generators to our critical systems, I think it makes sense to bring this same safety net to SaaS data. If you're asking AI to change 1,000 records in Salesforce or HubSpot, do you really expect it to blindly one-shot it without human review? What if it gets it wrong? How do you verify it?
You may be thinking "Don't these apps have built-in rollback mechanisms? What's the worst that can happen?" If you've seen what we've seen, you wouldn't be asking that.
The flux capacitor
Here's the model we believe works for this:
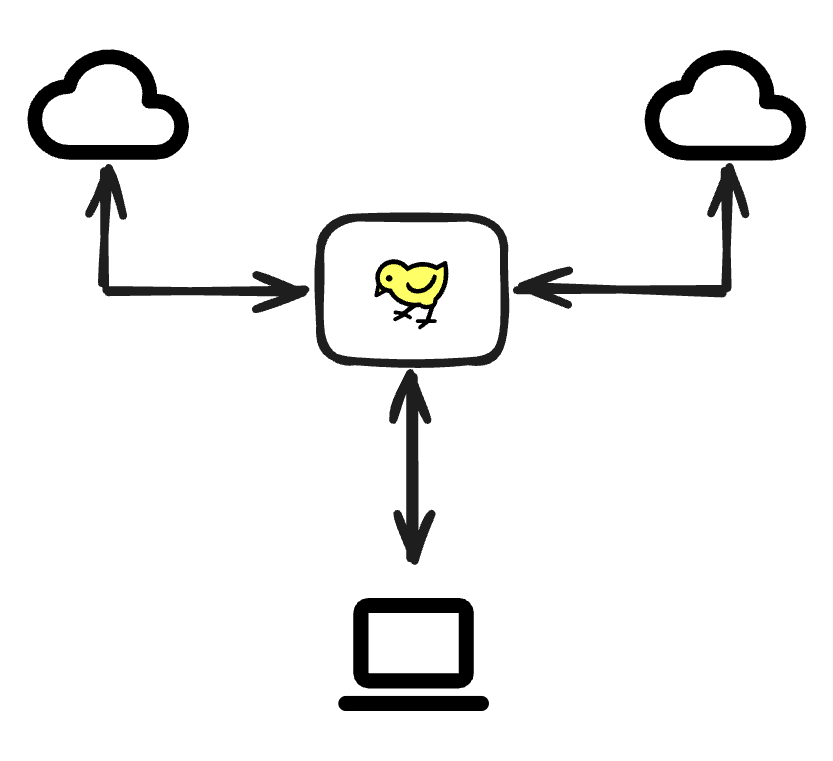
Look familiar? It's a lot like GitHub. You pull down files to your computer, you edit them, you push them back up, and they get deployed to your infrastructure. Scratch is the same kind of hub. Records get pulled in from your SaaS apps (Airtable, Webflow, Notion, HubSpot, Intercom). You make edits. Records get published back. You can copy data between SaaS apps too if that's your jam.
We also built a Scratch desktop app that gives you some key functionality:
A diff view for your records/files. When you stage 4,000 edits across your Webflow blog or your HubSpot contacts, you want to see them as a diff before you publish. I've asked Claude to make big edits without a diff view and it's terrifying. Having a bulk content diff viewer provides peace of mind.
Version history. When you (or someone else) messes up your data, either via AI or some random automation you have set up somewhere, it's so great to have a full version history of your data. You can just restore older changes from git.
Download/upload efficiency and correctness. Can you imagine if you had to manually download/upload your source code every time you worked on it? That'd be silly. This is solved by git when you have a persistent set of files.
Why git, specifically
We thought hard about whether to build our own thing to keep track of record versions. How hard could it be? There's a lot of logic behind storing records in Postgres and just storing a few versions in separate columns (this is how Whalesync works). Git was never designed to be a database for SaaS records.
We picked git anyway, for one product reason and two technical reasons.
The product reason: we wanted full version history. Saving before/after record data in a database is pretty simple, but saving the full history of a record is a lot more difficult. Building on top of the most popular VCS seemed like the best way to enable this. We could also benefit from all of the extra ecosystem tooling that's built on top of it.
The technical reasons: history is solved, transfer is solved. It's battle-tested. There are options for handling large repos if we need to go that route (e.g. Scalar). Plus it felt just the right amount of crazy that it'll be really cool if it scales.
How it's built
Five core parts:
- Next.js for the web client.
- NestJS + Postgres for the application backend, including auth, connectors, and background jobs.
- A Rust microservice that owns every git repo on disk, built on
gix. - An Electron desktop app that bundles a Rust CLI for local file operations.
- A standalone Rust CLI,
scratchmd, that exposes the same operations to the terminal (because Claude loves CLIs).
When you download your records to your computer, they're stored as raw JSON files in the exact same format that the API returns them in. We also have some hidden dot-prefixed folders that store extra data, including a bare git repo for version history.
As you approve changes, we add them to a JSON merge patch file (RFC 7396) that gets uploaded back to Scratch Web when you're ready to publish record edits.
Why Rust?
Mostly because gix is awesome. It's often faster than native git and we wanted a pure-Rust toolchain so we could ship a single static binary that runs in a container, runs in a CLI, and runs inside our desktop app (via napi-rs).
We've found that for a lot of the work we need to do, we're CPU-bound on lots of operations. When a user has 200,000 records and changes 50, the cost is not in talking to disk. It's in walking the tree, computing diffs, hashing blobs, and applying field-level patches. We lean heavily on gix's ability to read individual blobs out of a bare repo without ever materializing a worktree, which is O(changed files) instead of O(workspace size).
The bet
The reason we think now is the time for this category is that AI agents are about to bulk-edit business data at a scale humans never could.
If you're running a 10,000-product Shopify store, you need to give Claude access to make bulk edits but have a safe way to do so. You "clone" your store locally, make a huge set of changes, and iterate on it until it looks right. Then (if you're like us), you don't want to waste time and tokens to vibe code a script to save your data back to Shopify. That's boring mechanical work that someone else should solve for you.
If you've already adopted version control for your code, your infrastructure, and your marketing site, the case for adopting it for your business data is the same case, now that AI is here and wants to get its hands on all of your data in prod.