Most writing about AI alt text stops at "use a vision model." That skips the questions that decide whether the output is usable: which model, prompted how, fed an image at what size. So we ran the test. Six vision models, all of them on a laptop with no cloud API, across 26 images, with the model held constant while we varied the prompt, and the prompt held constant while we varied the resolution. Then we re-ran the winning combination on 20 images it had never seen, to check that the recipe holds.
Every number below comes from a local run you can reproduce with the commands in section 6. Nothing went to a hosted API, so there is no per-call bill and no rate limit hiding in the results. The token counts are still here, because if you would prefer to call a frontier model through an API, the input-token count is the number that sets your cost.
A note on house style before we start: this report was researched and written by the team at Scratch, the desktop app we built for editing a whole catalog of content at once. Section 9 is where alt text at that scale connects to what we sell, labeled as such. Everything before it is field notes.
What is inside
- Key findings
- Setup and method
- Variable one: the model
- Variable two: the prompt
- Variable three: image resolution
- The recipe we would ship
- Does it reproduce? A held-out run
- Limitations
- If you are doing this across a whole catalog
- Image sources and licenses
- Appendix: the full pipeline source
TL;DR, just give me the prompt. Send each image to a vision model with the prompt below, then enforce a 125-character cap. If the model goes over, re-ask it to "shorten to under 125 characters." Downscale images to about 768 px on the long edge first, because bigger is slower with no quality gain. The best local model in our tests was Qwen3-VL 30B through LM Studio. Any current frontier vision model works through an API.
Write production-ready alt text for this image for a SaaS company's website. Rules: - ONE line, MAXIMUM 125 characters. - Describe only what is actually visible. Do NOT guess locations, settings, people's names, or brands that are not clearly shown. - For a photo of a person, describe them plainly by apparent gender and clearly visible features, e.g. 'Woman with long dark hair in a white turtleneck, smiling'. Do not use vague labels like 'business professional' or 'person' when gender is clearly visible. - For a product illustration, diagram, or UI mockup, describe what the graphic DEPICTS (the product, tool, or workflow). Treat any sample or placeholder text shown inside a mockup as example content, NOT the subject. Do not make a placeholder word the main topic. - If readable product names or UI labels are clearly visible (e.g. Supabase, Notion, Webflow), you may include them. - Plain, specific language. Avoid subjective adjectives like sleek, futuristic, cheerful, professional, or modern. - Do NOT start with 'image of', 'photo of', 'screenshot of', or 'illustration of'. - No quotation marks. Output only the alt text.This exact prompt produced 0 errors and 0 over-limit results on a 20-image held-out set (section 7). Swap "a SaaS company's website" for your own context. The rest of this report is how we arrived at it.
1. Key findings
- Best overall: Qwen3-VL 30B. It reads on-screen labels, captures the subject of busy composite graphics, stays concise (2 of 26 outputs over the 125-character target), and runs at about 6.5 seconds per image once it is loaded.
- Turn off "thinking" on reasoning models, and know that the switch differs by vendor. Four of the six models reason by default, spending their whole token budget thinking and returning nothing usable. Disabling it makes them roughly 30 times faster with no quality loss. But the mechanism is not uniform: Gemma 4 and Qwen3.6 honor
reasoning_effort: "none", while GLM-4.6V ignores that field (andchat_template_kwargs) and only stops when you append a/nothinktoken to the prompt. Guess wrong and you get truncated output and a large hidden output-token bill. - Small models anchor on placeholder text. The 3B model described a product illustration as a tool for "automotive SEO optimization" because the demo mockup contained the word "Automotive." The larger models read that same word as sample content, not the subject.
- The prompt controls length and framing more than the model does. A free-form "describe this" prompt runs well past 125 characters. An explicit cap plus a one-line "shorten if over 125" pass reliably produces standards-compliant alt text.
- Cost is set by the image, and smaller models are not cheaper. Each image is a few hundred input tokens against only 20 to 40 output tokens, so cost is dominated by how a model tokenizes the picture. The 3B model used the most input tokens (about 1,560 per image) and the 30B Qwen the fewest (a flat 270), roughly six times fewer, despite being about ten times larger. Parameter count tells you nothing about API cost. The vision encoder does.
- For speed, architecture beats size. Qwen3-VL 30B (a mixture-of-experts model) ran at about 6.5 seconds per image, while the similarly sized but dense Qwen3.6 27B took about 27 seconds, four times slower, because every parameter fires on every token. For local throughput, prefer mixture-of-experts vision models.
- Resolution buys latency, not much quality. Qwen3-VL 30B read prominent UI labels even at 256 px. Going from 256 to 1536 px was about three to four times slower and roughly 17 times the payload for no reliable quality gain. Downscaling dense graphics to about 512 to 768 px is close to free.
- The recipe reproduces. Re-running the winning combination on 20 held-out images it had never seen produced 0 errors, 0 over-limit results, and the same flat 270 tokens per image.
2. Setup and method
Every model runs on-device through LM Studio, which exposes an OpenAI-compatible endpoint at http://localhost:1234/v1. Each request sends one image, as a base64 data URL, plus a text prompt to /v1/chat/completions:
def ask(model, prompt, img_path, max_tokens=300, reasoning_effort=None):
payload = {
"model": model,
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url",
"image_url": {"url": data_url(img_path)}},
],
}],
"temperature": 0.2,
"max_tokens": max_tokens,
}
if reasoning_effort is not None: # "none" disables thinking on Gemma 4 / Qwen3.6
payload["reasoning_effort"] = reasoning_effort
r = requests.post("http://localhost:1234/v1/chat/completions", json=payload)
...Every image is normalized before sending. We decode it (WebP and AVIF included), convert to RGB, downscale the long edge, and re-encode as JPEG, so format and size are controlled, not left to whatever the page served:
def data_url(path, max_side=768):
"""Normalize any format (webp/avif/png) to a downscaled JPEG data URL."""
im = Image.open(path)
im.load()
if im.mode != "RGB":
im = im.convert("RGB")
if max(im.size) > max_side:
im.thumbnail((max_side, max_side))
buf = io.BytesIO()
im.save(buf, format="JPEG", quality=85)
return "data:image/jpeg;base64," + base64.b64encode(buf.getvalue()).decode()The image set
The main study uses 26 images. Twelve are ours, scraped from our own marketing site (whalesync.com): headshots, clean UI screenshots, stylized product illustrations, a cartoon mascot, and busy marketing composites. Fourteen are openly licensed (CC0, public domain, or CC-BY), pulled from Openverse across deliberately different scenarios: portrait photos, landscapes, food, charts, flow diagrams, scanned documents, and artwork. Mixing our own product imagery with a generic open set keeps the findings from overfitting to one site's house style. Full attribution for every open image, including the 20 used later for validation, is in section 10.
A few words on how to read the tables:
- Chars is the character count of the alt text. The target is 125 or fewer, a common screen-reader and WCAG rule of thumb.
- Latency is wall-clock seconds on the test Mac (an Apple M1 Pro, 10 cores, 32 GB RAM). The first request to each model includes a one-time model load, so we report both median and max.
- Latency is hardware-specific. Treat it as relative across models, not as an absolute you will see on your own machine.
3. Variable one: the model
Same production prompt, same 26 images, across six local vision models spanning four families (Mistral, Google Gemma, Qwen, and Zhipu GLM), with two entries from the Qwen line, and ranging from 3B to 30B. Reasoning models ran with thinking disabled through their respective switch. Alongside quality and speed we report token usage, because for anyone weighing a hosted API, the input-token count, which includes the image, is the real cost driver.
| Model | Avg chars | Median latency | Max latency* | Input tok | Output tok | Est $/1k imgs† | Over 125c | Errors |
|---|---|---|---|---|---|---|---|---|
| Ministral 3B | 85 | 4.8 s | 7.3 s | 1562 | 27 | $0.33 | 0 | 0 |
| Gemma 4 12B | 108 | 5.0 s | 9.6 s | 489 | 24 | $0.11 | 3 | 0 |
| Gemma 4 26B | 102 | 6.1 s | 22.0 s | 489 | 21 | $0.11 | 0 | 0 |
| Qwen3-VL 30B (MoE) | 99 | 6.5 s | 15.4 s | 270 | 27 | $0.07 | 2 | 0 |
| Qwen3.6 27B (dense) | 120 | 27.1 s | 36.0 s | 282 | 24 | $0.07 | 12 | 0 |
| GLM-4.6V flash | 105 | 14.0 s | 16.7 s | 268 | 27 | $0.07 | 5 | 0 |
*Max latency is roughly the cold model-load on the first image. †Illustrative only: input and output tokens priced at $0.20 and $0.60 per million, a generic open-vision-model API rate. These models ran locally at no marginal cost. Use the column to compare models, not as a real invoice.
What we saw, model by model:
- Ministral 3B. Fast and concise, but the weakest reader and, surprisingly, the most token-expensive at about 1,560 input tokens per image. It paraphrases generically, anchors on demo text, and sometimes misses entirely. An oil portrait of a uniformed man came back as "abstract shapes and colors."
- Gemma 4 12B. A strong reader of UI labels ("Add Table Mapping") and scenes, but it runs long: 3 of 26 outputs over 125 characters, one at 167.
- Gemma 4 26B. Same vision tokenizer as the 12B (489 input tokens per image) but more disciplined: 0 over the limit against the 12B's 3, and a tighter average (102 against 108 characters). It also catches the occasional label the 12B skips. On the CMS illustration below it read the "ACME" brand header in the mockup, which the 12B reduced to "a website landing page." Within this family, the bigger model was the better-behaved one.
- Qwen3-VL 30B. The best balance: accurate across photos, charts, documents, and art, concise (2 of 26 slightly over), 0 errors, and the cheapest by far at a flat 270 input tokens per image regardless of content. Its one notable slip was calling a website mockup a "mobile app."
- Qwen3.6 27B. A capable reader but the wrong tool here. As a dense 27B it ran about 27 seconds per image, four times slower than the same-sized Qwen3-VL mixture-of-experts, and it was the most verbose model in the set at 12 of 26 over the limit. Cheap tokens, expensive wall-clock.
- GLM-4.6V flash. The other-family pick (Zhipu, 9B). Once thinking is off through
/nothinkit is accurate and cheap (268 input and 27 output tokens, 0 errors), reading labels like "CMS pSEO" and "Currently...". The trade-offs are about 14 seconds per image (slow for a 9B) and a little extra length. Before the/nothinkfix it reasoned by default, truncated on 10 of 26 images as it ran out of budget mid-thought, and spent roughly 20 times the output tokens. It is the clearest cautionary tale in the set.
Three images that drove those notes:
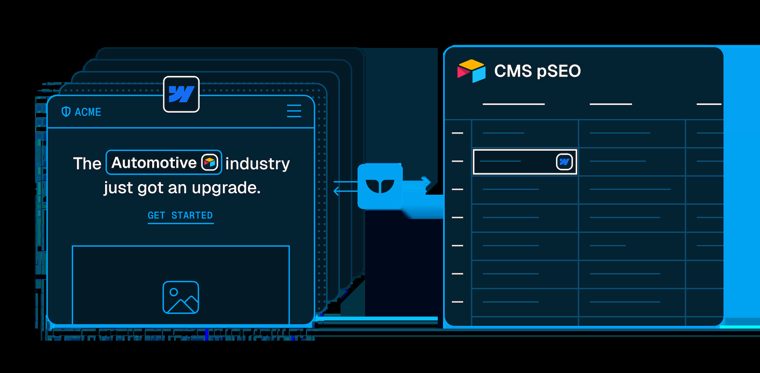
The CMS illustration. The mockup's sample copy mentions the automotive industry. Ministral 3B made that the subject ("a content management system interface for automotive SEO optimization"). Qwen3-VL and both Gemmas read it as on-screen sample text and described the actual product, a CMS dashboard. This single image is the case for the placeholder rule in section 4.

The oil portrait. Both Gemmas and Qwen described the uniform, the cap, and the pose. Ministral 3B returned "Artistic painting of abstract shapes and colors," a clean miss on a figurative portrait.
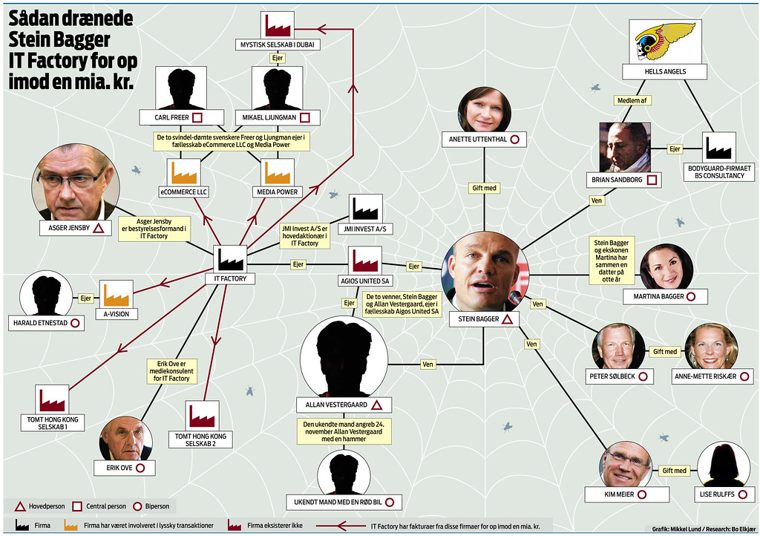
The network chart. Every model above the 3B read the proper nouns ("Stein Bagger," "IT Factory") straight off a busy news graphic. Reading printed names in a chart is a solved problem for these models. Inventing a subject from a placeholder is not.
4. Variable two: the prompt
Same model (Ministral 3B, the weakest reader, which makes the prompt's effect easy to see) and the same 12 owned images, across three prompt styles. Prompt choice swings output length far more than model choice does.
| Prompt style | What it asks for | Avg chars |
|---|---|---|
detailed |
Free-form: one descriptive sentence, no length cap. | 151 |
web_125 |
Web cap: a single line under 125 chars, name prominent UI or text. | 112 |
short_12w |
Terse: 12 words max, one line. | 51 |
The free-form prompt averages well past the 125-character target. An explicit cap pulls it into range. Three representative images, all three styles:

| Prompt style | Output | Chars |
|---|---|---|
detailed |
A professional portrait of an engaged individual smiling warmly against a modern, abstract background featuring soft geometric shapes and light tones. | 150 |
web_125 |
Professional woman smiling against modern office background with abstract geometric lighting. | 93 |
short_12w |
Woman smiling indoors wearing light top | 39 |
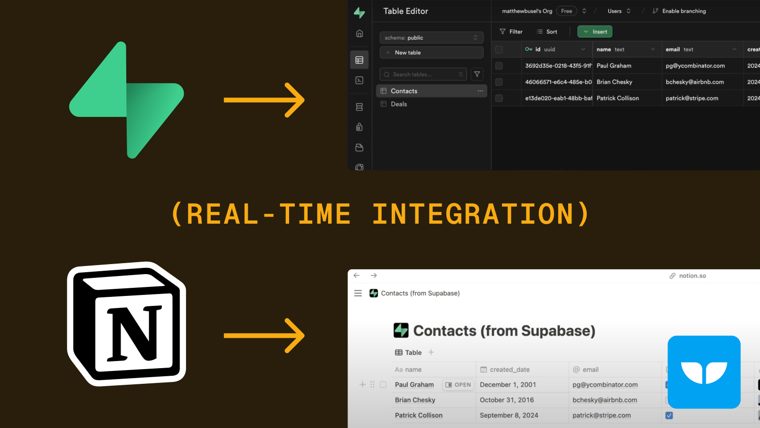
| Prompt style | Output | Chars |
|---|---|---|
detailed |
A sleek database interface displaying real-time data synchronization between Supabase and Notion, showcasing seamless integration capabilities. | 143 |
web_125 |
Real-time database integration displays Supabase table editor syncing with Notion's contact list. | 97 |
short_12w |
Database table syncing in Notion via Supabase real-time integration | 67 |
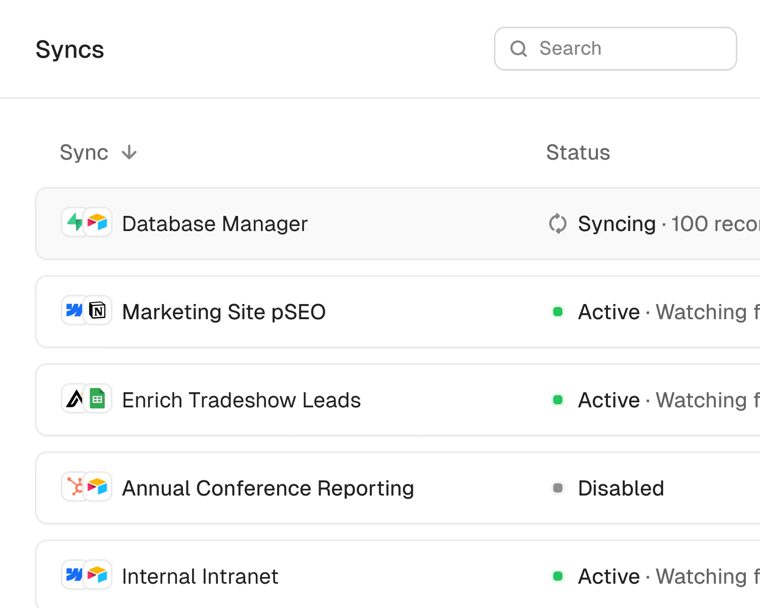
| Prompt style | Output | Chars |
|---|---|---|
detailed |
A dashboard showing active and syncing integrations for database management, marketing site optimization, lead enrichment, reporting tools, and internal intranet within a software system. | 187 |
web_125 |
SaaS sync dashboard showing active database integrations with status indicators for marketing site SEO, lead enrichment, conference reporting, and intranet systems | 163 |
short_12w |
Database sync status dashboard showing active and paused integrations | 69 |
That last row is the catch: even the capped web_125 prompt overshoots on a dense dashboard (163 characters). Length instructions move the average but do not guarantee the ceiling. That is why the production recipe adds a deterministic second pass.
The production prompt does two more things beyond length, and both showed up as quality wins:
- Describe people by apparent gender and visible features. The free-form prompt called the headshot "a professional portrait of an engaged individual." The rule turns that into "Woman with long dark hair in a white turtleneck, smiling." Specific beats polite.
- Treat placeholder text in a mockup as example content, not the subject. This is the rule that kills the "Automotive" failure from section 3.
The production prompt is the one in the TL;DR. A small cleanup pass strips the boilerplate models like to add ("Alt text:", wrapping quotes, stray special tokens):
def clean_alt(text):
"""Strip the junk models add around the actual alt text."""
t = text.strip()
t = re.sub(r'<\|[^|]*\|>', '', t) # GLM's <|begin_of_box|> wrappers
t = re.sub(r'^\s*alt[\s_-]*text\s*[:\-–]\s*', '', t, flags=re.I) # leading "Alt text:"
t = t.strip().strip('"“”‘’\'').strip() # wrapping quotes
return re.sub(r'\s+', ' ', t) # collapse whitespaceAnd because no model reliably obeys the character cap, a one-line text-only retry rewrites anything that spills over. It is generous with tokens so a reasoning model can think and still answer, and it keeps the original if the rewrite comes back empty:
def shrink(text, model):
prompt = (f"Rewrite this website alt text to be UNDER 125 characters while keeping "
"the most important information. One line, plain language, no quotes. "
f"Output only the rewritten alt text:\n\n{text}")
payload = {"model": model, "temperature": 0.2, "max_tokens": 512,
"messages": [{"role": "user", "content": prompt}]}
cand = clean_alt(post(payload))
return cand if cand and not cand.startswith("ERROR:") else text5. Variable three: image resolution
Fixed model (Qwen3-VL 30B) and prompt. The same image goes to the model at six max-side resolutions. We chose text-heavy UI images on purpose, because reading the labels is the hard part. The encoder is the same encode_at thumbnail step from section 2, just swept across sizes:
| Max side (px) | Mean payload | Median latency | Mean chars |
|---|---|---|---|
| 256 | 8 KB | 3.5 s | 137 |
| 384 | 16 KB | 3.7 s | 205 |
| 512 | 26 KB | 3.5 s | 139 |
| 768 | 48 KB | 4.6 s | 111 |
| 1024 | 75 KB | 5.9 s | 154 |
| 1536 | 138 KB | 11.9 s | 148 |
Median latency is shown because the first request of the run (256 px, first image) included a one-time model load of 31.5 s and would otherwise distort the smallest bucket. Mean character count is not monotonic, which is the point: more pixels did not buy a better description.
The result inverts the usual instinct. Three side-by-side demos, each sent at 256 px and at 640 px:
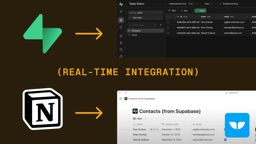
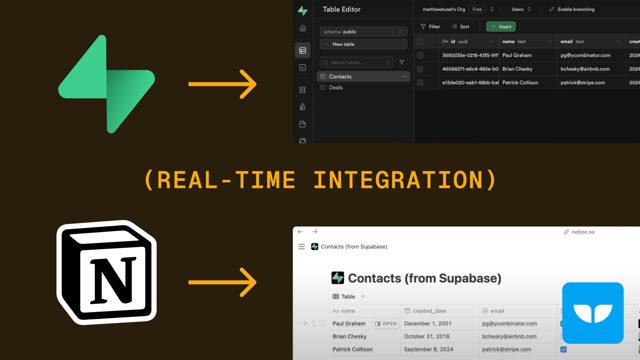
At 256 px Qwen3-VL still named "Supabase," "Notion," and "Webflow." At higher resolution it traded one of those for slightly different phrasing, not for more accuracy.
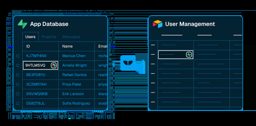
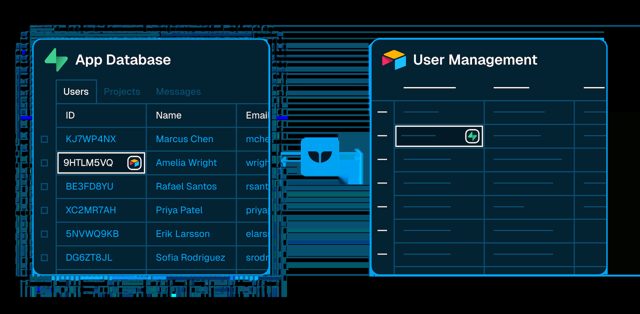
The "App Database" and "User Management" panel labels read fine at 256 px. The fine print inside the panels (column names, a highlighted row) only appears at higher resolution.
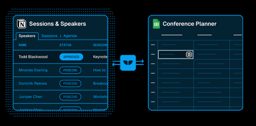
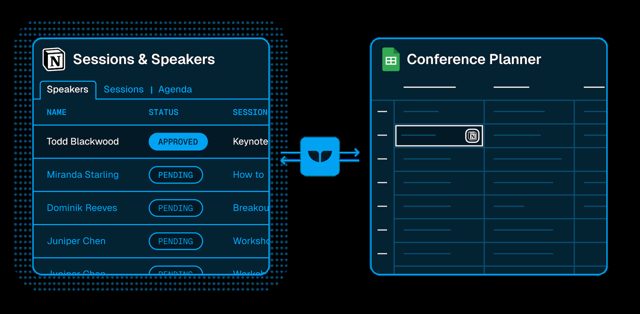
"Sessions & Speakers" and "Conference Planner" read at 256 px. At 1536 px the model added that the source was a Notion database and the target a Google Sheet, finer detail, but the core description was already right at the smallest size.
What this means in practice:
- This model is robust to downscaling. The prominent labels survive heavy compression because the illustrations use large, bold type. Only the fine print blurs out.
- Latency scales hard with resolution (about 3 seconds at 256 to 512 px, up to 12 seconds at 1536 px) and payload grows about 17 times, while quality does not improve along with it. LM Studio's encoder tiles the image to a fixed budget, so most of the extra pixels are wasted compute.
- Downscale dense graphics aggressively, to about 512 to 768 px, for a two-to-three-times latency win at negligible quality cost. Reserve higher resolution for genuinely small print.
6. The recipe we would ship
Putting the three variables together, the configuration we would run for this kind of image mix:
- Model. Qwen3-VL 30B: best quality and cheapest tokens. If you prefer the Gemma family, use Gemma 4 26B with
reasoning_effort: "none"(more disciplined than the 12B). Avoid the 3B for anything but plain photos. Through an API, any current frontier vision model works. - Prompt. The tightened production prompt from the TL;DR: apparent gender plus visible features for people, placeholder-as-example for mockups, 125 characters or fewer.
- Image. Normalize to JPEG and downscale to about 768 px on the long edge.
- Post-process. Strip the boilerplate, then run the one-line "shorten" retry to guarantee 125 characters or fewer.
To reproduce every number in this report:
python3 download_images.py https://whalesync.com --max 12 # our 12 owned images
python3 fetch_openverse.py # 14 openly-licensed images
python3 compare_models.py --models mistralai/ministral-3-3b google/gemma-4-12b-qat \
google/gemma-4-26b-a4b qwen/qwen3-vl-30b --reasoning-effort none --max-tokens 300
# ...add another model later as a column: compare_models.py --merge --models <id>
python3 alt_prompts.py # prompt sweep (Ministral)
python3 size_experiment.py # resolution sweep (Qwen)
python3 validate.py # held-out repeatability run7. Does it reproduce? A held-out run
A recipe that only works on the images you tuned it against is not a recipe. So we ran the winning configuration once, unchanged, Qwen3-VL 30B plus the tightened 125-character prompt plus 768 px plus the shorten pass, over 20 fresh openly-licensed images that were never used while developing it. The new set deliberately covers new categories: city, nature, sport, workspace, pie charts, schematics, maps, letters, still life, portrait, and vehicle.
| Run | Images | Avg chars | Input tok | Output tok | Est $/1k | Over 125c | Errors |
|---|---|---|---|---|---|---|---|
| Study set, Qwen3-VL 30B | 26 | 99 | 270 | 27 | $0.07 | 2 | 0 |
| Held-out validation | 20 | 96 | 270 | 23 | $0.07 | 0 | 0 |
The recipe reproduces. Twenty images, 0 errors, 0 over the 125-character limit, a flat 270 input tokens per image (identical to the study run), and about 4.8 seconds per image at steady state. Output length and cost match the study set within noise.
Every line of output from that run:
| Image (category) | Alt text (Qwen3-VL 30B at 768px) | Chars |
|---|---|---|
| city | White Art Deco building with decorative facade and fire escapes against a blue sky. | 83 |
| city | Night scene of a city street with illuminated buildings, a red bus, and people walking. | 87 |
| letter | Handwritten text in brown ink on a white background, with a small green and blue butterfly emblem in the corner. | 112 |
| letter | Handwritten letter on aged paper with a date of Sept. 8, 1944, in the upper right corner. | 89 |
| map | Vintage map collage with double-hemisphere projection, aged paper, and decorative elements. | 91 |
| map | Circular diagram showing planets and zodiac signs in orbits around the sun, labeled in Latin. | 93 |
| nature | A forest with tall trees and a branch holding a few orange leaves, set against a misty blue background. | 103 |
| nature | A black and white photo of a winding path through a forest with a large, gnarled tree branch arching overhead. | 110 |
| pie chart | Infographic showing statistics on food waste, including global and U.S. data, causes, costs, and environmental impact. | 118 |
| pie chart | Infographic showing drug production and usage statistics in the Americas with circular charts and a map. | 104 |
| portrait | Woman with dark hair lying on her back, arms raised above her head, hands open, in a black and white photograph. | 112 |
| schematic | Diagram of a control panel with labeled sections, knobs, switches, and handwritten notes. | 89 |
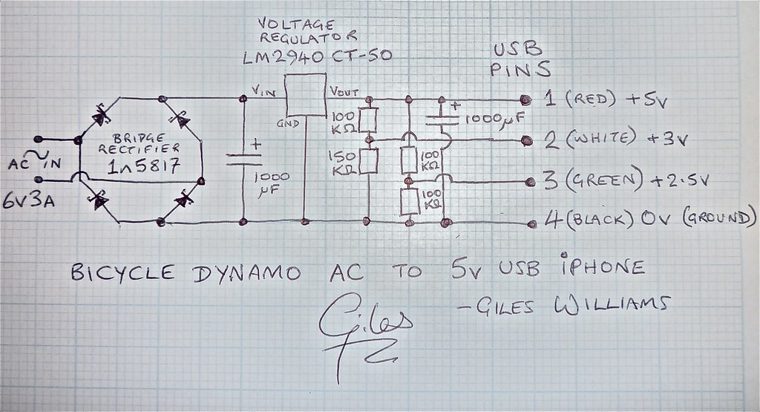
| schematic | Hand-drawn diagram of a bicycle dynamo AC to 5V USB adapter with bridge rectifier, voltage regulator, and USB pins. | 115 |
| sport | Empty green field with red seats and two tall light towers under a bright sky. | 78 |
| sport | Woman with dark hair in a ponytail wearing a purple jacket and visor, holding a black jacket and a tennis racket. | 113 |
| still life | Still life painting of fruit, a glass of red liquid, and a knife on a table. | 76 |
| still life | Still life painting with grapes, a lobster, fruit, and a glass on a dark table. | 79 |
| vehicle | Two diagrams of a vintage car with French labels identifying parts like the chassis, fender, and running board. | 111 |
| workspace | Two people at a desk with laptops and papers, one writing with a red pen. | 73 |
| workspace | Top-down view of a wooden desk with a laptop, tablet, coffee cup, glasses, and a small plant. | 93 |
The interesting failures were in the data, not the model. The keyword a query returned did not always match the picture, and Qwen described what was in the picture instead of forcing the expected label:


A "soccer match" query returned an empty stadium, and Qwen wrote "Empty green field with red seats and two tall light towers," not "a soccer match." An "antique map" query returned a zodiac chart, and Qwen wrote "Circular diagram showing planets and zodiac signs," not "a map." It described the schematic and the vintage-car diagram below by their actual labels too. The model did not hallucinate to match the keyword, which is exactly the behavior you want.

The only real friction was sourcing. One Openverse query ("man headshot studio") returned no openly-licensed results and the API rate-limited intermittently, so the first fetch yielded 18 of 20. Two supplemental queries topped it back up to 20. None of that touched the model output.
8. Limitations
- The sample is 26 images in the study and 20 in validation, across two sources. This is directional, not statistically powered. The quality verdicts are our judgment against the actual images, not a blind rubric.
- Latency is specific to one Apple M1 Pro and to LM Studio's current runtime. Absolute seconds will differ on other hardware.
- Quantization levels differ across these prebuilt LM Studio models, which muddies a pure "model capability" comparison.
- The dollar figures are illustrative. One assumed blended API price applied to measured tokens. Real providers price models differently, so treat the cost column as a comparison aid, not a quote.
- The open images came from keyword searches, so their exact content is incidental, useful for variety but not a curated benchmark.
- No accessibility expert reviewed the alt text. "Good" here means accurate, specific, and within length conventions.
9. If you are doing this across a whole catalog
This is the part where the research connects to what we build, labeled so you can skip it.
Running the recipe once is a script. Running it across every product image in a Shopify or Webflow catalog, every illustration in a CMS, every photo in a media library, and then reviewing each line before it ships, is the part that takes weeks by hand or gets handed to a plugin you cannot inspect. That review step is not optional: the tables above show even the best model overshoots the cap sometimes and occasionally calls a website a mobile app, so something has to catch those before they go live.
That is the job Scratch does. It pulls every record out of your platform into local files, your model writes the alt text there (not just for the first 200 rows), and you approve every change as a diff before anything publishes. The same shape applies whether the field is alt text, a meta description, or a product title. If you want the step-by-step version for one platform, we wrote up how to add alt text to every WordPress image with AI, and the Shopify SEO teardown covers where image alts sit in a larger on-page picture. This report is the kind of work we run on our own content.
10. Image sources and licenses
The 12 product images are ours (whalesync.com) and used with permission. The images below are openly licensed (CC0, public domain, or CC-BY) and were retrieved through Openverse: the 14 used in the study plus the 20 used for held-out validation, credited here so this report can be shared freely.
| Category | Title / creator | License | Source |
|---|---|---|---|
| photo-person | Portrait photograph | PDM 1.0 | flickr |
| photo-person | Pearls, Pearls, Pearls (cindy richardson) | BY 2.0 | flickr |
| photo-scene | Mountain lake with gate and figures | CC0 1.0 | rawpixel |
| photo-scene | Mountain lake scene (Ferdinand Katona) | CC0 1.0 | rawpixel |
| photo-food | Tofu croquettes on salad (Lablascovegmenu) | BY 2.0 | flickr |
| photo-food | Lunch at DCPS (DC Central Kitchen) | BY 2.0 | flickr |
| chart | Net closing in on missing Stein Bagger millions (Podknox) | BY 2.0 | flickr |
| chart | Financial statistics and accounting concept (paola.bazurto4) | BY 2.0 | flickr |
| diagram | The Self-Repair Manifesto, iFixit (dullhunk) | BY 2.0 | flickr |
| diagram | Using Social Media for Professional Learning (cambodia4kidsorg) | BY 2.0 | flickr |
| document | Diary (Barnaby) | BY 2.0 | flickr |
| document | Art Journal Template (Calsidyrose) | BY 2.0 | flickr |
| artwork | Portrait of a uniformed man (Jacques-Émile Blanche) | CC0 1.0 | rawpixel |
| artwork | Postinjohtaja Chr. Völschow, 1684 | CC0 1.0 | rawpixel |
| city | Eddy Street (dalecruse) | BY 2.0 | flickr |
| city | Big City Life, Berlin (matthias.ripp) | BY 2.0 | flickr |
| nature | Leafs in the winter fog (Gael Varoquaux) | BY 2.0 | flickr |
| nature | Over the Trail (Corey Leopold) | BY 2.0 | flickr |
| sport | Sydney Showground (edwin.11) | BY 2.0 | flickr |
| sport | Sania Mirza (Andrew Campbell Photography) | BY 2.0 | flickr |
| workspace | Writing Papers (Helloquence) | CC0 1.0 | stocksnap |
| workspace | Macbook Laptop (Lia Leslie) | CC0 1.0 | stocksnap |
| pie-chart | The Big Food Wasters (GDS Infographics) | BY 2.0 | flickr |
| pie-chart | Illegal Drugs in the Americas (GDS Infographics) | BY 2.0 | flickr |
| schematic | Control Display from Apollo 13 (jurvetson) | BY 2.0 | flickr |
| schematic | Bicycle dynamo USB adapter (aegidian) | BY 2.0 | flickr |
| map | Assorted Maps brush set (webtreats) | BY 2.0 | flickr |
| map | Planisphaerium Ptolemaicum (Leventhal Map Center, BPL) | BY 2.0 | flickr |
| letter | Write more Letters (Markus Reinhardt) | BY 2.0 | flickr |
| letter | letter (Lizbeth King) | BY 2.0 | flickr |
| still-life | Still Life with Fruit and Sweetmeats, 1635 (Georg Flegel) | CC0 1.0 | rawpixel |
| still-life | Still Life with Fruit and Lobster (Pieter de Ring) | CC0 1.0 | rawpixel |
| portrait | Art of gymnastics (lauragrb) | BY 2.0 | flickr |
| vehicle | Nomenclature automobile en 1927 (claude-22) | PDM 1.0 | flickr |
11. Appendix: the full pipeline source
Every script that produced the numbers above, complete and runnable. They share a small request layer (gen_alt_text.py) and talk only to a local LM Studio endpoint. Click to expand.
download_images.py · scrape and download images from a web page
#!/usr/bin/env python3
"""Download images from a web page (or pages) into ./images.
Usage:
python3 download_images.py # defaults to whalesync.com
python3 download_images.py https://example.com # one or more URLs
python3 download_images.py URL --max 15 # cap number of images
"""
import argparse
import hashlib
import os
import re
import sys
from urllib.parse import urljoin, urlparse
import requests
from bs4 import BeautifulSoup
UA = (
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/124.0 Safari/537.36"
)
OUT_DIR = os.path.join(os.path.dirname(os.path.abspath(__file__)), "images")
# Skip vector/icon formats that raster vision models can't ingest well.
SKIP_EXT = {".svg", ".ico", ".gif"}
def largest_from_srcset(srcset: str) -> str | None:
"""Pick the highest-resolution candidate from a srcset attribute."""
best_url, best_w = None, -1
for part in srcset.split(","):
bits = part.strip().split()
if not bits:
continue
url = bits[0]
w = 0
if len(bits) > 1 and bits[1].endswith("w"):
try:
w = int(bits[1][:-1])
except ValueError:
w = 0
if w >= best_w:
best_url, best_w = url, w
return best_url
def collect_image_urls(page_url: str) -> list[str]:
r = requests.get(page_url, headers={"User-Agent": UA}, timeout=30)
r.raise_for_status()
soup = BeautifulSoup(r.text, "html.parser")
urls: list[str] = []
for img in soup.find_all("img"):
cand = None
if img.get("srcset"):
cand = largest_from_srcset(img["srcset"])
if not cand:
cand = img.get("src") or img.get("data-src")
if cand:
urls.append(urljoin(page_url, cand))
# <picture><source srcset=...></picture>
for source in soup.find_all("source"):
if source.get("srcset"):
cand = largest_from_srcset(source["srcset"])
if cand:
urls.append(urljoin(page_url, cand))
# og:image
og = soup.find("meta", property="og:image")
if og and og.get("content"):
urls.append(urljoin(page_url, og["content"]))
return urls
def filename_for(url: str, content_type: str) -> str:
path = urlparse(url).path
base = os.path.basename(path) or "image"
base = re.sub(r"[^A-Za-z0-9._-]", "_", base)
root, ext = os.path.splitext(base)
if not ext:
ext = {
"image/jpeg": ".jpg",
"image/png": ".png",
"image/webp": ".webp",
}.get(content_type.split(";")[0].strip(), ".jpg")
base = root + ext
# Prefix with a short URL hash to avoid collisions across pages.
h = hashlib.sha1(url.encode()).hexdigest()[:8]
return f"{h}_{base}"
def main():
ap = argparse.ArgumentParser()
ap.add_argument("urls", nargs="*", default=["https://whalesync.com"],
help="page URL(s) to scrape (default: https://whalesync.com)")
ap.add_argument("--max", type=int, default=20, help="max images to download")
ap.add_argument("--min-bytes", type=int, default=5000,
help="skip images smaller than this (filters icons/spacers)")
args = ap.parse_args()
urls = args.urls or ["https://whalesync.com"]
os.makedirs(OUT_DIR, exist_ok=True)
# Gather + dedupe candidate image URLs across all pages.
seen_urls, candidates = set(), []
for page in urls:
try:
found = collect_image_urls(page)
except Exception as e:
print(f"!! failed to scrape {page}: {e}", file=sys.stderr)
continue
print(f" {page}: found {len(found)} <img>/source candidates")
for u in found:
if u in seen_urls:
continue
ext = os.path.splitext(urlparse(u).path)[1].lower()
if ext in SKIP_EXT:
continue
seen_urls.add(u)
candidates.append(u)
print(f"\n{len(candidates)} unique candidate images; downloading up to {args.max}\n")
saved, seen_hashes = 0, set()
for u in candidates:
if saved >= args.max:
break
try:
resp = requests.get(u, headers={"User-Agent": UA}, timeout=30)
resp.raise_for_status()
data = resp.content
except Exception as e:
print(f" skip (error) {u}: {e}")
continue
if len(data) < args.min_bytes:
print(f" skip (too small {len(data)}b) {u}")
continue
digest = hashlib.sha1(data).hexdigest()
if digest in seen_hashes:
print(f" skip (duplicate bytes) {u}")
continue
seen_hashes.add(digest)
ct = resp.headers.get("Content-Type", "")
if "image" not in ct and not os.path.splitext(u)[1]:
print(f" skip (not image, {ct}) {u}")
continue
fname = filename_for(u, ct)
with open(os.path.join(OUT_DIR, fname), "wb") as f:
f.write(data)
saved += 1
print(f" [{saved}] {fname} ({len(data)//1024} KB)")
print(f"\nDone. {saved} images in {OUT_DIR}")
if __name__ == "__main__":
main()fetch_openverse.py · pull openly-licensed images from Openverse
#!/usr/bin/env python3
"""Fetch openly-licensed images (Openverse API) with license + attribution.
CC0 / public-domain / CC-BY only, recorded so the shareable report can credit them.
python3 fetch_openverse.py # main set -> ./images
python3 fetch_openverse.py --set val # held-out validation set -> ./images_val
"""
import argparse
import hashlib
import io
import json
import os
import requests
from PIL import Image
HERE = os.path.dirname(os.path.abspath(__file__))
API = "https://api.openverse.org/v1/images/"
UA = "alt-text-research/1.0 (local eval)"
# (slug, query, category-or-None)
CATEGORIES_MAIN = [
("photo-person", "portrait person face", "photograph"),
("photo-scene", "mountain landscape lake", "photograph"),
("photo-animal", "dog puppy outdoors", "photograph"),
("photo-food", "plate of food meal", "photograph"),
("chart", "bar chart graph statistics", None),
("diagram", "flowchart process diagram", None),
("document", "scanned document page text", None),
("artwork", "oil painting portrait", "digitized_artwork"),
]
# Deliberately different queries so the validation set is genuinely held-out.
CATEGORIES_VAL = [
("portrait", "man headshot studio", "photograph"),
("city", "city street architecture", "photograph"),
("nature", "forest trees path", "photograph"),
("sport", "soccer match action", "photograph"),
("workspace", "laptop desk office", "photograph"),
("pie-chart", "pie chart infographic", None),
("schematic", "circuit diagram schematic", None),
("map", "antique map illustration", None),
("letter", "handwritten letter vintage", None),
("still-life", "still life painting fruit", "digitized_artwork"),
]
MIN_BYTES, MAX_BYTES = 15_000, 8_000_000
def search(query, category):
params = {"q": query, "license": "cc0,pdm,by", "page_size": 12, "mature": "false"}
if category:
params["category"] = category
r = requests.get(API, params=params, headers={"User-Agent": UA}, timeout=30)
r.raise_for_status()
return r.json().get("results", [])
def main():
ap = argparse.ArgumentParser()
ap.add_argument("--set", choices=["main", "val"], default="main")
ap.add_argument("--per", type=int, default=2, help="images per category")
args = ap.parse_args()
cats = CATEGORIES_MAIN if args.set == "main" else CATEGORIES_VAL
out_dir = os.path.join(HERE, "images" if args.set == "main" else "images_val")
meta_path = os.path.join(HERE, "images_meta.json" if args.set == "main"
else "images_val_meta.json")
os.makedirs(out_dir, exist_ok=True)
meta = json.load(open(meta_path)) if os.path.exists(meta_path) else {}
# Dedupe against anything already downloaded in either set.
seen_hashes = set()
for d in ("images", "images_val"):
dp = os.path.join(HERE, d)
if os.path.isdir(dp):
for fn in os.listdir(dp):
try:
seen_hashes.add(hashlib.sha1(open(os.path.join(dp, fn), "rb").read()).hexdigest())
except Exception:
pass
for slug, query, category in cats:
print(f"=== {slug}: '{query}' ===")
got = 0
try:
results = search(query, category)
except Exception as e:
print(f" !! search failed: {e}")
continue
for item in results:
if got >= args.per:
break
url = item.get("url")
if not url:
continue
try:
resp = requests.get(url, headers={"User-Agent": UA}, timeout=30)
resp.raise_for_status()
data = resp.content
except Exception as e:
print(f" skip (dl error) {url[:55]}: {e}")
continue
if not (MIN_BYTES <= len(data) <= MAX_BYTES):
continue
digest = hashlib.sha1(data).hexdigest()
if digest in seen_hashes:
continue
try:
im = Image.open(io.BytesIO(data)); im.load()
if min(im.size) < 200:
continue
ext = (im.format or "JPEG").lower().replace("jpeg", "jpg")
except Exception:
continue
seen_hashes.add(digest)
fname = f"ov_{slug}_{got+1}_{digest[:6]}.{ext}"
with open(os.path.join(out_dir, fname), "wb") as f:
f.write(data)
meta[fname] = {
"category": slug, "title": item.get("title"), "creator": item.get("creator"),
"license": (item.get("license") or "").upper(),
"license_version": item.get("license_version"),
"source": item.get("source"), "landing": item.get("foreign_landing_url"),
}
got += 1
print(f" [{got}] {fname} ({len(data)//1024} KB) {meta[fname]['license']} {im.size}")
if got == 0:
print(" (no usable results)")
with open(meta_path, "w") as f:
json.dump(meta, f, indent=2)
n = len([k for k in meta])
print(f"\nDone. {n} images recorded in {os.path.basename(meta_path)} (set={args.set})")
if __name__ == "__main__":
main()gen_alt_text.py · the request layer: send an image to a local model and parse the reply
#!/usr/bin/env python3
"""Generate alt text for every image in ./images using local LM Studio models.
LM Studio exposes an OpenAI-compatible API at http://localhost:1234/v1.
Usage:
python3 gen_alt_text.py --probe # test which models accept images
python3 gen_alt_text.py # full run over all images/models
python3 gen_alt_text.py --models qwen/qwen3-vl-30b google/gemma-4-12b-qat
python3 gen_alt_text.py --prompt "Write alt text in <= 12 words."
"""
import argparse
import base64
import glob
import json
import os
import subprocess
import time
import io
import requests
from PIL import Image
HERE = os.path.dirname(os.path.abspath(__file__))
IMG_DIR = os.path.join(HERE, "images")
API = "http://localhost:1234/v1/chat/completions"
# Candidate vision models already downloaded in LM Studio, ordered fastest
# -> slowest so the report fills in quickly (the reasoning model is last).
DEFAULT_MODELS = [
"mistralai/ministral-3-3b",
"google/gemma-4-12b-qat",
"qwen/qwen3-vl-30b",
"google/gemma-4-26b-a4b",
"mistralai/ministral-3-14b-reasoning",
]
DEFAULT_PROMPT = (
"Write concise, descriptive alt text for this image to be used on a website. "
"Describe the key visual content in one sentence. Be specific about what is "
"shown. Do not begin with 'image of', 'picture of', or 'a screenshot of'. "
"Output only the alt text, nothing else."
)
MAX_SIDE = 1024 # downscale longest edge before sending (speed + sanity)
def data_url(path: str) -> str:
"""Normalize any format (webp/avif/png/...) to a downscaled JPEG data URL."""
im = Image.open(path)
im.load()
if im.mode != "RGB":
im = im.convert("RGB")
if max(im.size) > MAX_SIDE:
im.thumbnail((MAX_SIDE, MAX_SIDE))
buf = io.BytesIO()
im.save(buf, format="JPEG", quality=85)
b64 = base64.b64encode(buf.getvalue()).decode()
return f"data:image/jpeg;base64,{b64}"
def ask_full(model: str, prompt: str, img_path: str, timeout: int,
max_tokens: int = 1024, reasoning_effort: str | None = None,
base_url: str = API, headers: dict | None = None) -> tuple[str, float, dict]:
"""Return (alt_text_or_error, seconds, usage). Errors are prefixed 'ERROR:'.
usage = {prompt, completion, total, reasoning, cost} (values may be None).
`base_url`/`headers` make this provider-agnostic (LM Studio default; an
OpenAI-compatible cloud endpoint like OpenRouter can be passed in).
Reasoning models (Gemma-4, ministral-*-reasoning) emit chain-of-thought into
a separate reasoning_content field; the real answer is in content. A generous
max_tokens lets them finish thinking AND answer. Alternatively pass
reasoning_effort='none' to disable thinking entirely (much faster, no truncation).
"""
payload = {
"model": model,
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": data_url(img_path)}},
],
}],
"temperature": 0.2,
"max_tokens": max_tokens,
}
if reasoning_effort is not None:
payload["reasoning_effort"] = reasoning_effort
t0 = time.time()
try:
r = requests.post(base_url, json=payload, timeout=timeout, headers=headers)
dt = time.time() - t0
if r.status_code != 200:
return f"ERROR: HTTP {r.status_code}: {r.text[:200]}", dt, {}
j = r.json()
ch = j["choices"][0]
u = j.get("usage", {}) or {}
det = u.get("completion_tokens_details", {}) or {}
usage = {"prompt": u.get("prompt_tokens"), "completion": u.get("completion_tokens"),
"total": u.get("total_tokens"), "reasoning": det.get("reasoning_tokens"),
"cost": u.get("cost")} # cost present only on some providers (OpenRouter)
text = (ch["message"].get("content") or "").strip()
if not text:
if ch.get("finish_reason") == "length":
return "ERROR: truncated (ran out of tokens while reasoning)", dt, usage
return "ERROR: empty response", dt, usage
return text, dt, usage
except Exception as e:
return f"ERROR: {e}", time.time() - t0, {}
def ask(model: str, prompt: str, img_path: str, timeout: int,
max_tokens: int = 1024, reasoning_effort: str | None = None) -> tuple[str, float]:
"""Backward-compatible wrapper that drops the usage dict."""
text, dt, _ = ask_full(model, prompt, img_path, timeout, max_tokens, reasoning_effort)
return text, dt
def unload_all():
"""Free VRAM/RAM before loading the next model (best effort)."""
subprocess.run(["lms", "unload", "--all"], capture_output=True)
def probe(models, prompt, timeout):
imgs = sorted(glob.glob(os.path.join(IMG_DIR, "*")))
if not imgs:
print("No images in ./images — run download_images.py first.")
return
test_img = imgs[0]
print(f"Probing {len(models)} models with: {os.path.basename(test_img)}\n")
for m in models:
unload_all()
out, dt = ask(m, prompt, test_img, timeout)
ok = not out.startswith("ERROR:")
tag = "VISION OK " if ok else "NO/ERROR "
preview = out.replace("\n", " ")[:90]
print(f" [{tag}] {m:42s} {dt:5.1f}s {preview}")
def run(models, prompt, timeout):
imgs = sorted(glob.glob(os.path.join(IMG_DIR, "*")))
if not imgs:
print("No images in ./images — run download_images.py first.")
return
print(f"{len(imgs)} images x {len(models)} models\n")
results = {os.path.basename(p): {} for p in imgs}
def flush():
with open(os.path.join(HERE, "results.json"), "w") as f:
json.dump({"prompt": prompt, "models": models, "results": results},
f, indent=2)
build_report(models, prompt, results)
for m in models:
print(f"=== {m} ===")
unload_all()
for p in imgs:
name = os.path.basename(p)
out, dt = ask(m, prompt, p, timeout)
results[name][m] = {"text": out, "seconds": round(dt, 1)}
preview = out.replace("\n", " ")[:70]
print(f" {name:34s} {dt:5.1f}s {preview}")
flush() # incremental: report.html updates after every image
print()
print("Wrote results.json and report.html")
def build_report(models, prompt, results):
rows = []
for name, by_model in results.items():
cells = []
for m in models:
r = by_model.get(m, {})
txt = (r.get("text") or "").replace("<", "<").replace(">", ">")
secs = r.get("seconds", "")
err = txt.startswith("ERROR:")
cells.append(
f'<td class="{ "err" if err else "" }">{txt}'
f'<div class="meta">{secs}s</div></td>'
)
rows.append(
f'<tr><td class="img"><img src="images/{name}"><div class="meta">{name}</div></td>'
+ "".join(cells) + "</tr>"
)
head = "".join(f"<th>{m}</th>" for m in models)
html = f"""<!doctype html><meta charset="utf-8">
<title>Alt text comparison</title>
<style>
body{{font:14px/1.5 -apple-system,sans-serif;margin:24px;color:#111}}
.prompt{{background:#f4f4f5;padding:10px 14px;border-radius:8px;margin-bottom:16px}}
table{{border-collapse:collapse;width:100%}}
th,td{{border:1px solid #ddd;padding:10px;vertical-align:top;text-align:left}}
th{{background:#fafafa;position:sticky;top:0}}
td.img{{width:200px}} td.img img{{max-width:180px;max-height:140px;display:block}}
td{{width:320px}}
.meta{{color:#888;font-size:12px;margin-top:6px}}
.err{{color:#b00;background:#fff5f5}}
</style>
<h1>Alt text comparison</h1>
<div class="prompt"><b>Prompt:</b> {prompt}</div>
<table><tr><th>Image</th>{head}</tr>{''.join(rows)}</table>
"""
with open(os.path.join(HERE, "report.html"), "w") as f:
f.write(html)
def main():
ap = argparse.ArgumentParser()
ap.add_argument("--models", nargs="+", default=DEFAULT_MODELS)
ap.add_argument("--prompt", default=DEFAULT_PROMPT)
ap.add_argument("--timeout", type=int, default=300)
ap.add_argument("--probe", action="store_true",
help="just test which models accept images (1 image)")
args = ap.parse_args()
if args.probe:
probe(args.models, args.prompt, args.timeout)
else:
run(args.models, args.prompt, args.timeout)
if __name__ == "__main__":
main()alt_prompts.py · sweep prompt styles on a single model
#!/usr/bin/env python3
"""Compare alt-text PROMPT styles on a single model (default: ministral-3-3b).
Runs each candidate prompt over every image in ./images and builds
report_prompts.html with one column per prompt, plus character counts
(good web alt text is generally <= 125 chars).
python3 alt_prompts.py
python3 alt_prompts.py --model qwen/qwen3-vl-30b
"""
import argparse
import glob
import json
import os
import re
from gen_alt_text import ask, unload_all, HERE, IMG_DIR
MODEL = "mistralai/ministral-3-3b"
# Candidate prompt styles to compare. Tweak freely.
PROMPTS = {
"detailed": (
"Write descriptive alt text for this image for a software company's "
"website. One sentence describing the key visual content. Do not start "
"with 'image of' or 'screenshot of'. Output only the alt text."
),
"web_125": (
"Write production-ready alt text for this image as it would appear on a "
"SaaS marketing website. Requirements: a single line UNDER 125 characters; "
"describe the most important visual content and any prominent UI or text; "
"plain, specific language; do NOT start with 'image of', 'photo of', "
"'screenshot of', or 'illustration of'; no quotation marks. "
"Output only the alt text."
),
"short_12w": (
"Write very short alt text for this image: at most 12 words, one line, "
"no ending punctuation, no quotes, do not start with 'image of' or "
"'screenshot of'. Output only the alt text."
),
}
def clean_alt(text: str) -> str:
"""Strip the junk models add around the actual alt text."""
if text.startswith("ERROR:"):
return text
t = text.strip()
# Strip model-specific special tokens, e.g. GLM's <|begin_of_box|> wrappers.
t = re.sub(r'<\|[^|]*\|>', '', t)
# Drop a leading label like "Alt text:" / "Alt-text -" etc.
t = re.sub(r'^\s*alt[\s_-]*text\s*[:\-–]\s*', '', t, flags=re.I)
# Remove wrapping single/double/smart quotes.
t = t.strip().strip('"“”‘’\'').strip()
# Collapse internal whitespace/newlines to single spaces.
t = re.sub(r'\s+', ' ', t)
return t
def main():
ap = argparse.ArgumentParser()
ap.add_argument("--model", default=MODEL)
ap.add_argument("--timeout", type=int, default=300)
args = ap.parse_args()
imgs = sorted(glob.glob(os.path.join(IMG_DIR, "*")))
if not imgs:
print("No images in ./images — run download_images.py first.")
return
print(f"Model: {args.model}\n{len(imgs)} images x {len(PROMPTS)} prompts\n")
unload_all() # load the one model once
results = {os.path.basename(p): {} for p in imgs}
def flush():
with open(os.path.join(HERE, "results_prompts.json"), "w") as f:
json.dump({"model": args.model, "prompts": PROMPTS,
"results": results}, f, indent=2)
build_report(args.model, results)
for key, prompt in PROMPTS.items():
print(f"=== prompt: {key} ===")
for p in imgs:
name = os.path.basename(p)
raw, dt = ask(args.model, prompt, p, args.timeout)
txt = clean_alt(raw)
results[name][key] = {"text": txt, "chars": len(txt),
"seconds": round(dt, 1)}
print(f" {name[:28]:28s} {len(txt):3d}c {dt:4.1f}s {txt[:60]}")
flush()
print()
print("Wrote results_prompts.json and report_prompts.html")
def build_report(model, results):
keys = list(PROMPTS.keys())
rows = []
for name, by in results.items():
cells = []
for k in keys:
r = by.get(k, {})
txt = (r.get("text") or "").replace("<", "<").replace(">", ">")
chars = r.get("chars", "")
over = isinstance(chars, int) and chars > 125
err = txt.startswith("ERROR:")
cls = "err" if err else ("over" if over else "")
cells.append(
f'<td class="{cls}">{txt}'
f'<div class="meta">{chars} chars · {r.get("seconds","")}s</div></td>'
)
rows.append(
f'<tr><td class="img"><img src="images/{name}">'
f'<div class="meta">{name}</div></td>' + "".join(cells) + "</tr>"
)
head = "".join(
f'<th>{k}<div class="meta">{PROMPTS[k][:60]}…</div></th>' for k in keys
)
html = f"""<!doctype html><meta charset="utf-8">
<title>Alt-text prompt comparison — {model}</title>
<style>
body{{font:14px/1.5 -apple-system,sans-serif;margin:24px;color:#111}}
h1 .meta{{font-weight:400}}
table{{border-collapse:collapse;width:100%}}
th,td{{border:1px solid #ddd;padding:10px;vertical-align:top;text-align:left}}
th{{background:#fafafa;font-size:13px}}
td.img{{width:200px}} td.img img{{max-width:180px;max-height:140px;display:block}}
td{{width:300px}}
.meta{{color:#888;font-size:12px;margin-top:6px;font-weight:400}}
.over{{background:#fff8e6}} .err{{color:#b00;background:#fff5f5}}
</style>
<h1>Alt-text prompt comparison <span class="meta">— {model}</span></h1>
<p class="meta">Amber = over 125 characters.</p>
<table><tr><th>Image</th>{head}</tr>{''.join(rows)}</table>
"""
with open(os.path.join(HERE, "report_prompts.html"), "w") as f:
f.write(html)
if __name__ == "__main__":
main()make_alt_text.py · production run with boilerplate cleanup and the shorten retry
#!/usr/bin/env python3
"""Produce production-ready alt text for every image in ./images.
Model: ministral-3-3b (LM Studio). Balanced style, hard <=125 char cap with a
text-only 'shorten' retry for any that spill over.
Outputs: alt_text.json, alt_text.csv, report_final.html
python3 make_alt_text.py
"""
import argparse
import csv
import glob
import json
import os
import requests
from gen_alt_text import ask, data_url, unload_all, HERE, IMG_DIR, API
from alt_prompts import clean_alt
MODEL = "mistralai/ministral-3-3b"
LIMIT = 125
PROMPT = (
"Write production-ready alt text for this image for a SaaS company's website.\n"
"Rules:\n"
"- ONE line, MAXIMUM 125 characters.\n"
"- Describe only what is actually visible. Do NOT guess locations, settings, "
"people's names, or brands that are not clearly shown.\n"
"- For a photo of a person, describe them plainly by apparent gender and clearly "
"visible features, e.g. 'Woman with long dark hair in a white turtleneck, smiling'. "
"Do not use vague labels like 'business professional' or 'person' when gender is "
"clearly visible.\n"
"- For a product illustration, diagram, or UI mockup, describe what the graphic "
"DEPICTS (the product, tool, or workflow). Treat any sample or placeholder text "
"shown inside a mockup as example content, NOT the subject — do not make a "
"placeholder word the main topic.\n"
"- If readable product names or UI labels are clearly visible (e.g. Supabase, "
"Notion, Webflow), you may include them.\n"
"- Plain, specific language. Avoid subjective adjectives like sleek, futuristic, "
"cheerful, professional, or modern.\n"
"- Do NOT start with 'image of', 'photo of', 'screenshot of', or 'illustration of'.\n"
"- No quotation marks. Output only the alt text."
)
def shrink(text: str, timeout: int, model: str = MODEL) -> str:
"""Text-only pass: rewrite an over-long alt text to fit under the limit.
max_tokens is generous so reasoning models can think and still answer; if the
rewrite comes back empty/errored, we keep the original rather than lose it.
"""
prompt = (
f"Rewrite this website alt text to be UNDER {LIMIT} characters while keeping "
"the most important information. One line, plain language, no quotes. "
f"Output only the rewritten alt text:\n\n{text}"
)
payload = {"model": model, "temperature": 0.2, "max_tokens": 512,
"messages": [{"role": "user", "content": prompt}]}
try:
r = requests.post(API, json=payload, timeout=timeout)
if r.status_code == 200:
cand = clean_alt(r.json()["choices"][0]["message"].get("content") or "")
if cand and not cand.startswith("ERROR:"):
return cand
except Exception:
pass
return text
def main():
ap = argparse.ArgumentParser()
ap.add_argument("--timeout", type=int, default=300)
args = ap.parse_args()
imgs = sorted(glob.glob(os.path.join(IMG_DIR, "*")))
if not imgs:
print("No images in ./images — run download_images.py first.")
return
print(f"{MODEL}: writing alt text for {len(imgs)} images (<= {LIMIT} chars)\n")
unload_all()
out = {}
for p in imgs:
name = os.path.basename(p)
raw, dt = ask(MODEL, PROMPT, p, args.timeout)
alt = clean_alt(raw)
tries = 0
while len(alt) > LIMIT and not alt.startswith("ERROR:") and tries < 2:
alt = shrink(alt, args.timeout)
tries += 1
flag = "" if len(alt) <= LIMIT else " (still over)"
out[name] = {"alt": alt, "chars": len(alt)}
print(f" {name[:30]:30s} {len(alt):3d}c {dt:4.1f}s{flag} {alt}")
# JSON
with open(os.path.join(HERE, "alt_text.json"), "w") as f:
json.dump(out, f, indent=2)
# CSV
with open(os.path.join(HERE, "alt_text.csv"), "w", newline="") as f:
w = csv.writer(f)
w.writerow(["filename", "alt_text", "chars"])
for name, r in out.items():
w.writerow([name, r["alt"], r["chars"]])
# HTML
rows = []
for name, r in out.items():
alt = r["alt"].replace("<", "<").replace(">", ">")
over = r["chars"] > LIMIT
rows.append(
f'<tr><td class="img"><img src="images/{name}">'
f'<div class="meta">{name}</div></td>'
f'<td class="{ "over" if over else "" }">{alt}'
f'<div class="meta">{r["chars"]} chars</div></td></tr>'
)
html = f"""<!doctype html><meta charset="utf-8">
<title>Final alt text — {MODEL}</title>
<style>
body{{font:15px/1.55 -apple-system,sans-serif;margin:24px;color:#111}}
table{{border-collapse:collapse;width:100%;max-width:1000px}}
td{{border:1px solid #ddd;padding:12px;vertical-align:top}}
td.img{{width:220px}} td.img img{{max-width:200px;max-height:150px;display:block}}
.meta{{color:#888;font-size:12px;margin-top:6px}}
.over{{background:#fff8e6}}
</style>
<h1>Final alt text <span class="meta">— {MODEL}, ≤{LIMIT} chars</span></h1>
<table>{''.join(rows)}</table>
"""
with open(os.path.join(HERE, "report_final.html"), "w") as f:
f.write(html)
over = sum(1 for r in out.values() if r["chars"] > LIMIT)
print(f"\nWrote alt_text.json, alt_text.csv, report_final.html "
f"({len(out)} images, {over} over {LIMIT} chars)")
if __name__ == "__main__":
main()compare_models.py · the model-comparison harness (the main study)
#!/usr/bin/env python3
"""Compare models head-to-head on the SAME production alt-text prompt.
Same PROMPT, clean-up, and <=125 char cap (with shorten retry) as make_alt_text,
so differences are purely the model. Builds a side-by-side report.
python3 compare_models.py # ministral vs gemma-4-12b
python3 compare_models.py --models mistralai/ministral-3-3b google/gemma-4-26b-a4b qwen/qwen3-vl-30b
"""
import argparse
import glob
import json
import os
from gen_alt_text import ask_full, unload_all, HERE, IMG_DIR
from alt_prompts import clean_alt
from make_alt_text import PROMPT, LIMIT, shrink
DEFAULT_MODELS = ["mistralai/ministral-3-3b", "google/gemma-4-12b-qat"]
def main():
ap = argparse.ArgumentParser()
ap.add_argument("--models", nargs="+", default=DEFAULT_MODELS)
ap.add_argument("--timeout", type=int, default=400)
ap.add_argument("--max-tokens", type=int, default=1024,
help="reasoning models (Gemma-4) need ~4000 on complex images")
ap.add_argument("--reasoning-effort", default=None,
help="set to 'none' to disable thinking on reasoning models (fast)")
ap.add_argument("--prompt-suffix", default="",
help="appended to the prompt, e.g. ' /nothink' to disable GLM thinking")
ap.add_argument("--only", nargs="+", default=None,
help="only images whose filename contains one of these substrings")
ap.add_argument("--merge", action="store_true",
help="add these models as columns to existing results_compare.json "
"instead of overwriting (lets you add one model later)")
args = ap.parse_args()
imgs = sorted(glob.glob(os.path.join(IMG_DIR, "*")))
if args.only:
imgs = [p for p in imgs
if any(s in os.path.basename(p) for s in args.only)]
if not imgs:
print("No images in ./images — run download_images.py first.")
return
print(f"{len(imgs)} images x {len(args.models)} models (<= {LIMIT} chars)\n")
path = os.path.join(HERE, "results_compare.json")
existing = json.load(open(path)) if (args.merge and os.path.exists(path)) else {}
ex_res, ex_models = existing.get("results", {}), existing.get("models", [])
# Report shows existing columns first, then any newly-added models.
report_models = ex_models + [m for m in args.models if m not in ex_models]
results = {os.path.basename(p): dict(ex_res.get(os.path.basename(p), {}))
for p in imgs}
def flush():
with open(path, "w") as f:
json.dump({"prompt": PROMPT, "models": report_models,
"results": results}, f, indent=2)
build_report(report_models, results)
for m in args.models:
print(f"=== {m} ===")
unload_all()
for p in imgs:
name = os.path.basename(p)
raw, dt, usage = ask_full(m, PROMPT + args.prompt_suffix, p, args.timeout,
max_tokens=args.max_tokens,
reasoning_effort=args.reasoning_effort)
alt = clean_alt(raw)
tries = 0
while len(alt) > LIMIT and not alt.startswith("ERROR:") and tries < 2:
alt = shrink(alt, args.timeout, model=m)
tries += 1
results[name][m] = {"text": alt, "chars": len(alt), "seconds": round(dt, 1),
"ptok": usage.get("prompt"), "ctok": usage.get("completion"),
"rtok": usage.get("reasoning")}
pt, ctk = usage.get("prompt"), usage.get("completion")
print(f" {name[:24]:24s} {len(alt):3d}c {dt:5.1f}s {str(pt):>4}+{str(ctk):<4}tok {alt[:42]}")
flush()
print()
print("Wrote results_compare.json and report_compare.html")
def build_report(models, results):
# Per-model summary (averages over completed cells).
summary_cells = []
for m in models:
cells = [by[m] for by in results.values() if m in by]
ok = [c for c in cells if not (c.get("text") or "").startswith("ERROR:")]
errs = len(cells) - len(ok)
over = sum(1 for c in ok if c.get("chars", 0) > LIMIT)
avg_c = round(sum(c.get("chars", 0) for c in ok) / len(ok)) if ok else 0
avg_s = round(sum(c.get("seconds", 0) for c in ok) / len(ok), 1) if ok else 0
pt = [c["ptok"] for c in ok if c.get("ptok")]
ct = [c["ctok"] for c in ok if c.get("ctok")]
avg_pt = round(sum(pt) / len(pt)) if pt else 0
avg_ct = round(sum(ct) / len(ct)) if ct else 0
summary_cells.append(
f"<td><b>{avg_c}</b> avg chars · <b>{avg_s}s</b> avg<br>"
f"<span class='meta'>{avg_pt} in + {avg_ct} out tok/img · "
f"{over} over {LIMIT}c · {errs} errors</span></td>"
)
summary = (f"<tr><th>summary</th>{''.join(summary_cells)}</tr>")
rows = []
for name, by in results.items():
cells = []
for m in models:
r = by.get(m, {})
txt = (r.get("text") or "").replace("<", "<").replace(">", ">")
chars = r.get("chars", "")
over = isinstance(chars, int) and chars > LIMIT
err = txt.startswith("ERROR:")
cls = "err" if err else ("over" if over else "")
tok = ""
if r.get("ptok") or r.get("ctok"):
tok = f' · {r.get("ptok","?")}+{r.get("ctok","?")} tok'
cells.append(
f'<td class="{cls}">{txt}'
f'<div class="meta">{chars} chars · {r.get("seconds","")}s{tok}</div></td>'
)
rows.append(
f'<tr><td class="img"><img src="images/{name}">'
f'<div class="meta">{name[:24]}</div></td>' + "".join(cells) + "</tr>"
)
head = "".join(f"<th>{m}</th>" for m in models)
html = f"""<!doctype html><meta charset="utf-8">
<title>Model comparison — alt text</title>
<style>
body{{font:14px/1.5 -apple-system,sans-serif;margin:24px;color:#111}}
table{{border-collapse:collapse;width:100%}}
th,td{{border:1px solid #ddd;padding:10px;vertical-align:top;text-align:left}}
th{{background:#fafafa;position:sticky;top:0}}
td.img{{width:200px}} td.img img{{max-width:180px;max-height:140px;display:block}}
td{{width:330px}}
.meta{{color:#888;font-size:12px;margin-top:6px}}
.over{{background:#fff8e6}} .err{{color:#b00;background:#fff5f5}}
</style>
<h1>Model comparison — production alt-text prompt</h1>
<p class="meta">Amber = over {LIMIT} characters. Gemma-4 run with thinking disabled (reasoning_effort=none).</p>
<table><tr><th>Image</th>{head}</tr>{summary}{''.join(rows)}</table>
"""
with open(os.path.join(HERE, "report_compare.html"), "w") as f:
f.write(html)
if __name__ == "__main__":
main()size_experiment.py · sweep input resolution for a fixed model
#!/usr/bin/env python3
"""Variable: IMAGE SIZE. Sweep input resolution for a fixed model + prompt.
Sends the same text-heavy UI images at several max-side resolutions and records
the alt text, latency, and payload size — to find the resolution floor below
which the model can no longer read on-screen labels.
python3 size_experiment.py
"""
import base64
import io
import json
import os
import time
import requests
from PIL import Image
from gen_alt_text import unload_all, HERE, IMG_DIR, API
from make_alt_text import PROMPT
MODEL = "qwen/qwen3-vl-30b"
SIZES = [256, 384, 512, 768, 1024, 1536]
# Text-heavy UI images (large originals) where legibility should matter most.
IMAGES = ["6f9ab5e5", "bddc34c3", "a86c45b5"]
def encode_at(path: str, size: int):
im = Image.open(path)
im.load()
if im.mode != "RGB":
im = im.convert("RGB")
im.thumbnail((size, size)) # only downscales, never upscales
buf = io.BytesIO()
im.save(buf, format="JPEG", quality=85)
raw = buf.getvalue()
return ("data:image/jpeg;base64," + base64.b64encode(raw).decode(),
f"{im.size[0]}x{im.size[1]}", len(raw))
def ask_data_url(data_url: str, timeout: int = 120):
payload = {
"model": MODEL, "temperature": 0.2, "max_tokens": 300,
"reasoning_effort": "none",
"messages": [{"role": "user", "content": [
{"type": "text", "text": PROMPT},
{"type": "image_url", "image_url": {"url": data_url}}]}],
}
t0 = time.time()
r = requests.post(API, json=payload, timeout=timeout)
dt = time.time() - t0
if r.status_code != 200:
return f"ERROR: HTTP {r.status_code}", dt
return (r.json()["choices"][0]["message"].get("content") or "").strip(), dt
def main():
import glob
paths = []
for sub in IMAGES:
hits = glob.glob(os.path.join(IMG_DIR, f"*{sub}*")) or \
[p for p in glob.glob(os.path.join(IMG_DIR, "*")) if sub in os.path.basename(p)]
if hits:
paths.append(hits[0])
print(f"{MODEL}: {len(paths)} images x {len(SIZES)} sizes\n")
unload_all()
results = {}
for p in paths:
name = os.path.basename(p)
results[name] = {}
print(f"=== {name} ===")
for s in SIZES:
data_url, px, kb = encode_at(p, s)
text, dt = ask_data_url(data_url)
results[name][s] = {"text": text, "chars": len(text),
"seconds": round(dt, 1), "px": px,
"kb": round(kb / 1024, 1)}
print(f" size {s:4d} -> {px:>9} {kb/1024:5.1f}KB {dt:4.1f}s {len(text):3d}c {text[:55]}")
with open(os.path.join(HERE, "results_size.json"), "w") as f:
json.dump({"model": MODEL, "prompt": PROMPT, "sizes": SIZES,
"results": results}, f, indent=2)
print()
print("Wrote results_size.json")
if __name__ == "__main__":
main()validate.py · the held-out repeatability run
#!/usr/bin/env python3
"""Repeatability / validation pass: run the study's BEST combo on a held-out set.
Best combo = Qwen3-VL-30B + tightened <=125 prompt + 768px + shorten-pass
Held-out set = ./images_val (20 images never seen during the study)
Writes results_validation.json. Reports any issues (errors, over-limit, slow).
"""
import glob
import json
import os
import gen_alt_text
gen_alt_text.MAX_SIDE = 768 # the validated resolution sweet spot
from gen_alt_text import ask_full, unload_all, HERE # noqa: E402
from alt_prompts import clean_alt # noqa: E402
from make_alt_text import PROMPT, LIMIT, shrink # noqa: E402
MODEL = "qwen/qwen3-vl-30b"
VAL_DIR = os.path.join(HERE, "images_val")
def main():
imgs = sorted(glob.glob(os.path.join(VAL_DIR, "*")))
if not imgs:
print("No images in ./images_val — run fetch_openverse.py --set val")
return
print(f"Validation: {MODEL} @768px on {len(imgs)} held-out images\n")
unload_all()
out = {}
for p in imgs:
name = os.path.basename(p)
raw, dt, usage = ask_full(MODEL, PROMPT, p, timeout=300, max_tokens=300)
alt = clean_alt(raw)
tries = 0
while len(alt) > LIMIT and not alt.startswith("ERROR:") and tries < 2:
alt = shrink(alt, 300, model=MODEL)
tries += 1
out[name] = {"alt": alt, "chars": len(alt), "seconds": round(dt, 1),
"ptok": usage.get("prompt"), "ctok": usage.get("completion")}
flag = ""
if alt.startswith("ERROR:"):
flag = " <<ERROR"
elif len(alt) > LIMIT:
flag = " <<OVER"
print(f" {name[:30]:30s} {len(alt):3d}c {dt:4.1f}s {usage.get('prompt')}tok {alt[:46]}{flag}")
with open(os.path.join(HERE, "results_validation.json"), "w") as f:
json.dump({"model": MODEL, "prompt": PROMPT, "max_side": gen_alt_text.MAX_SIDE,
"results": out}, f, indent=2)
errs = [n for n, r in out.items() if r["alt"].startswith("ERROR:")]
over = [n for n, r in out.items() if not r["alt"].startswith("ERROR:") and r["chars"] > LIMIT]
print(f"\n{len(out)} images | errors: {len(errs)} | over {LIMIT}c: {len(over)}")
if errs:
print(" errors:", errs)
if over:
print(" over-limit:", over)
print("Wrote results_validation.json")
if __name__ == "__main__":
main()All inference for this report ran on-device through LM Studio. No image or prompt left the machine, and no cloud API was called. Our product images are © whalesync.com, used here for evaluation.